Two parrots perching on a tree branch A black cat is sleeping, head on a computerA white dog sitting on a couch1122345A dog looking bashfully to the side6191630图像-文本-标签空间中的统一对比学习0...
”统一对比学习 图像-文本-标签空间 零样本识别 线性探测 迁移学习“ 的搜索结果
SOTA计算机视觉系统经过训练可以预测一组固定的预定目标类别。这种受限的监督形式限制了它们的通用性和可用...预训练后,使用自然语言来引用学习的视觉概念(或描述新的视觉概念),从而实现模型零样本传输到下游任务。
人工智能-项目实践-迁移学习-基于迁移学习的光谱分析,用于解决小样本无标签迁移学习 基于迁移学习的光谱分析,用于解决小样本无标签迁移学习
GTNet:用于零样本目标检测的生成迁移网络 摘要: 提出了一种用于零样本目标检测的生成迁移网络(GTNet)。GTNet由目标检测模块和知识迁移模块组成。目标检测模块可以学习大规模的已知领域知识;知识迁移模块利用...
一项调查JianfeiYang,YuecongXu,HaozhiCao,HanZou,LihuaXie新加坡南洋理工大学电子电气工程学院A R T I C L E I N F O保留字:人类活动识别深度学习迁移学习领域自适应动作识别免设备A B标准无设备活动识别在...
一项调查JianfeiYang,YuecongXu,HaozhiCao,HanZou,LihuaXie新加坡南洋理工大学电子电气工程学院A R T I C L E I N F O保留字:人类活动识别深度学习迁移学习领域自适应动作识别免设备A B标准无设备活动识别在...
今天给大家带来一个文本生成图像的案例。让大家都成为艺术家,自己电脑也能生成图片 ,该模型它能让数十亿人在几秒钟内创建出精美的艺术。 Stable Diffusion模型包括两个步骤: 前向扩散——通过逐渐扰动输入数据将...
一项调查JianfeiYang,YuecongXu,HaozhiCao,HanZou,LihuaXie新加坡南洋理工大学电子电气工程学院A R T I C L E I N F O保留字:人类活动识别深度学习迁移学习领域自适应动作识别免设备A B标准无设备活动识别在...

本文提出了用于无语言文本到图像生成的 LAFITE2, 它使用检索增强伪文本特征构建和潜在特征优化来提升性能。该方法有益于各种设置,包括少样本、半监督和全监督学习;它可以应用于不同的模型,包括 GAN 和扩散模型。
CLIP作者提出了一种基于对比学习的多模态预训练模型CLIP,该模型打破了传统视觉模型只能在预定义的标签列表中识别这一范式,是一个zero-shot的视觉分类模型,并且预训练的模型在没有微调的情况下,可以在下游任务上...
作者介绍了针对SAR(合成孔径雷达)、多光谱、高光谱、VHR(超高分辨率图像)和异源图像等不同变化检测数据集的有监督、无监督和半监督深度学习技术,并分析其优缺点,讨论了一些重大挑战。
智能系统与应用16(2022)200137深度剩余网络与迁移学习型人才重新识别Arpita Guptaa,*,Pratik Pawadeb,Ramadoss Balakrishnan ba印度海得拉巴Koneru Lakshmaiah教育基金会计算机科学与工程系b印度...
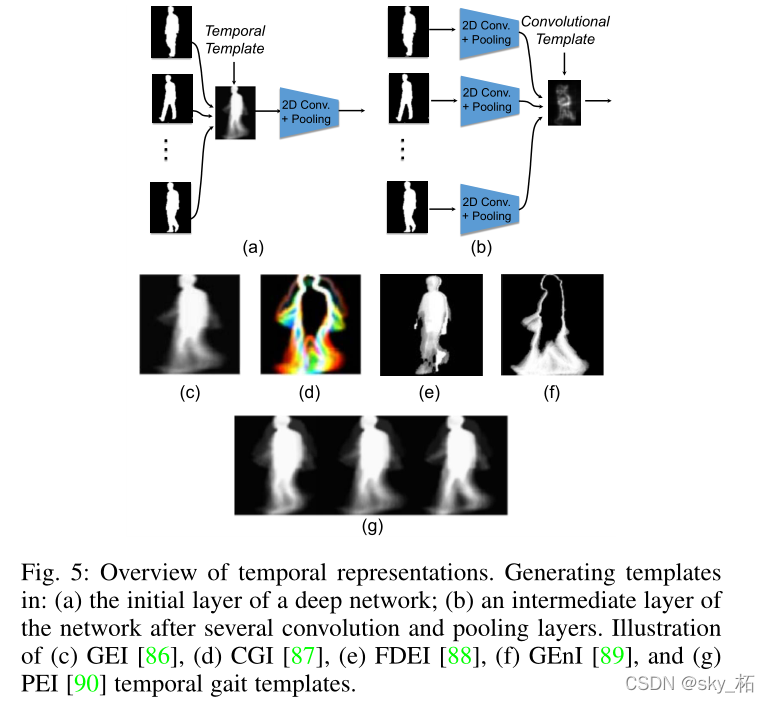



目标检测的目的是识别出图像中感兴趣的物体并将其定位,相比于传统手工提取图像特征的方法,基于深度学习的目标检测方法更加高效。同时,由于无人机工作的空域环境较为复杂,的范围,可见光遥感探测技术及其成像器件...
从表中可以看出,在URPC数据集上,本文算法⑽在URPC数据集上获得了最优的UIQM和NIQE得分,这表明,本文算法得到的增强图像在量化上的。本文基于MWCNN提出了改进型的水下图像增强模型,和S,其中C和W分别表示其输入的...
在如今电子产品快速发展的时代,智能化、机械化、信息化逐步代替了传统 行业的发展和经营模式,人工智能越来越贴近人们的日常生活,计算机更加频繁 的出现在各种生产生活场景中,成为不可或缺的电子设备。...
随着海洋强国战略的提出,占地球表面积71%的海洋成为现阶段最热门的探索领域之一。海洋中蕴含着丰富的资源,但是水下可见度低、压力大且...水下目标检测的目的是定位和识别水下场景中的目标。陆地上的目标检测技术的。

在本文中,我们提出了一个通过时间和上下文对比(TS-TCC)的无监督时间序列表示学习框架,从未标记的数据中学习时间序列表示。首先,使用弱增强和强增强将原始时间序列数据转换为两个不同但相关的视图。其次,我们提出...
为了应对这两个挑战:视觉语言模型(VLMs)最近得到了深入研究,该模型能从互联网上几乎无穷无尽的网络规模图像-文本对中学习丰富的视觉-语言相关性,并通过单个 VLM 对各种视觉识别任务进行zero-shot预测。...
5206线性探头CLIPCoOpProDA(我们的)Zero-ShotCLIP----即时分布学习刘宇宁1*,李建庄2,张永刚1,刘雅静1,田新梅1<$1中国科学技术大学2华为诺亚{lyn 0,yonggang,lyj 123} @ mail.ustc.edu.cn,刘建庄@ huawei....
本文是清华大学智能技术与系统国家重点实验室近期发表的深度迁移学习综述,首次定义了深度迁移学习的四个分类,包括基于实例、映射、网络和对抗的迁移学习方法,并在每个方向上都给出了丰富的参考文献。机器之心对该...
9970时变对比视频表示学习西蒙·珍妮·海林金土坯研究{jenni,hljin} @ adobe.com摘要我们引入了一种新的自监督对比学习方法,从未标记的视频中学习表示现有的方法忽略了输入失真的细节,通过学习时间变换的不变性。...
182390基于元对比网络的自监督视频表示学习0Yuanze Lin 1 * Xun Guo 2 Yan Lu 201 华盛顿大学,2 微软亚洲研究院[email protected], { xunguo, yanlu } @microsoft.com0摘要0自监督学习已成功应用于预...
受自然语言处理(NLP)中提示学习研究的最新进展的启发,我们提出了上下文优化(CoOp),这是一种简单的方法,专门用于将类似clip的视觉语言模型用于下游图像识别。具体地说,CoOp用可学习的向量对提示的上下文词建模,...
推荐文章
- php 上传图片 缩略图,PHP 图片上传类 缩略图-程序员宅基地
- scrapy爬虫框架_3.6.1 scrapy 的版本-程序员宅基地
- 微信支付——统一下单——java_小程序统一下单接口-程序员宅基地
- (已解决)报错 ValueError: Tensor conversion requested dtype float32 for Tensor with dtype resource-程序员宅基地
- 记录el-table树形数据,默认展开折叠按钮失效_eltable一刷新展开的子节点展开按钮消失-程序员宅基地
- 设计模式复习-桥接模式_csdn天使也掉毛-程序员宅基地
- CodeForces - 894A-QAQ(思维)_"qaq\" is a word to denote an expression of crying-程序员宅基地
- java毕业生设计移动学习网站计算机源码+系统+mysql+调试部署+lw-程序员宅基地
- 14种神笔记方法,只需选择1招,让你的学习和工作效率提高100倍!_1秒笔记 高级-程序员宅基地
- 最新java毕业论文英文参考文献_计算机毕业论文javaweb英文文献-程序员宅基地